 At the heart of an LPG are three key components: nodes, relationships (or edges), and properties. Nodes typically represent entities, such as a person, place, or thing, and each node can have an associated label indicating its type. Relationships connect these nodes, denoting how they are related to one another. Both nodes and relationships can possess properties, which are essentially key-value pairs offering additional information about them.
At the heart of an LPG are three key components: nodes, relationships (or edges), and properties. Nodes typically represent entities, such as a person, place, or thing, and each node can have an associated label indicating its type. Relationships connect these nodes, denoting how they are related to one another. Both nodes and relationships can possess properties, which are essentially key-value pairs offering additional information about them. At the core of an RDF Knowledge Graph are three fundamental components: subject, predicate, and object, which together form a “triple”. Subjects and objects are entities (or resources), while predicates express the relationships between these entities. Subjects and predicates are identified by URIs (Uniform Resource Identifiers), whereas objects can be either URIs or literals (like a text string or number).
At the core of an RDF Knowledge Graph are three fundamental components: subject, predicate, and object, which together form a “triple”. Subjects and objects are entities (or resources), while predicates express the relationships between these entities. Subjects and predicates are identified by URIs (Uniform Resource Identifiers), whereas objects can be either URIs or literals (like a text string or number).|
Database |
Vendor |
Link |
|---|---|---|
|
GraphDB |
Ontotext |
|
|
Stardog |
Stardog Union |
|
|
Amazon Neptune |
Amazon Web Services |
|
|
AllegroGraph |
Franz inc. |
|
|
MarkLogic |
Progress |
|
|
RDFox |
Oxford Semantic |
Closing the gap to LPGs – Addition of RDF*
RDF-star (or RDF*) and the associated query language SPARQL-star (also written as SPARQL*) are the most widely supported extension of the existing standards. RDF* goes beyond the expressivity of Property Graphs in that one can make statements about statements, formally called statement-level annotations. For instance, one can provide a time span for a relationship or attach key-value pairs to relationships. The statement-level annotations enable a more efficient representation of scores, weights, temporal restrictions and provenance information.
In the original RDF standard (i.e. RDF1.1) this could only be achieved using suboptimal methods such as re-ification, which involved creating additional statements to represent metadata, leading to unnecessarily complex and convoluted graph structures.
The addition of RDF* has allowed the RDF standard to provides a more fine-grained approach to capturing metadata and additional contextual information. This enables the enrichment of data with annotations that can be used for various purposes, such as describing data quality, trustworthiness, temporal validity, or uncertainty. The ability to attach annotations directly to individual statements empowers users with a more nuanced representation of information.
Use Cases: Where RDF Knowledge Graphs Shine
RDF Knowledge Graphs have been widely adopted in areas where interoperability, standardisation, and semantic richness are paramount. They are extensively used in scholarly data, semantic search engines, digital libraries, bioinformatics, and linked open data projects.
RDF Knowledge Graphs are recognised for their universal interoperability. Since RDF is a standard model developed by the World Wide Web Consortium (W3C), RDF datasets can be readily combined or shared across different applications without loss of meaning. This is particularly important for open data initiatives and for organisations looking to integrate diverse data sources.
Another key advantage of RDF is its strong support for ontology. Through languages such as RDFS (RDF Schema) and OWL (Web Ontology Language), RDF Knowledge Graphs can encode rich semantics and complex hierarchies, providing a way to define explicit, machine-understandable domain models
When it comes to expressing and exploiting ontology, RDF proves to be an incredibly powerful tool. It’s not only capable of describing hierarchical classification (taxonomy) but also complex relationships between entities, and it carries these descriptive capabilities across a universal standard, lending immense interoperability.
RDF Knowledge Graphs, with their standardisation, interoperability, and robust semantics, provide a potent framework for linking and inferring data across an organisation.
Use case: Data Provenance
Statement-level annotations in RDF enable the inclusion of data provenance, which provides information about the origin and history of data within the graph design. Data provenance is significant as the interpretation of the same information can vary based on its history and context, such as the source of the data and how it was processed.
The introduction of statement-level annotations in RDF (via RDF*) simplifies the implementation of data provenance. Consequently, RDF becomes more suitable for applications that necessitate regulatory compliance and auditing. It can be utilised to audit transformations of datasets and evaluate the confidence levels in the data’s validity.
Example applications within this use case:
-
Data Versioning and Provenance Tracking: RDF databases provide a robust foundation for data versioning and provenance tracking, essential for applications that require tracking changes and maintaining historical context. By associating metadata and timestamps with RDF triples, data practitioners can track the origin, modification history, and lineage of data over time. This provenance information can be invaluable for data quality analysis, auditing, reproducibility, and data governance. RDF databases offer the ability to query and analyse data based on different versions, enabling temporal-aware analysis and understanding of data evolution.
-
Scientific Research and Reproducibility: In scientific research, data provenance is vital for ensuring reproducibility and transparency. RDF databases provide a semantic representation that allows scientists to capture detailed information about the experimental setup, data collection methods, processing steps, and analysis workflows. By associating provenance metadata with RDF triples, researchers can trace the origin of data, understand the transformations it has undergone, and reproduce experiments reliably. RDF’s flexible structure enables the integration of provenance information with scientific data, enabling comprehensive documentation and sharing of research findings.
-
Data Governance and Compliance: RDF databases support data governance efforts by capturing data provenance and facilitating compliance with regulatory requirements. Provenance information helps organisations ensure data integrity, traceability, and accountability. By associating metadata, timestamps, and authorship information with RDF triples, organisations can track the lineage of data, monitor data usage, and ensure compliance with data protection regulations. RDF’s standardised representation and support for ontologies enable the definition and enforcement of data governance policies, making it easier to manage and control data throughout its lifecycle.
-
Data Integration and Trustworthiness: RDF databases excel at integrating heterogeneous data from diverse sources, and provenance information enhances the trustworthiness of integrated datasets. By associating provenance metadata with RDF triples, data integration workflows can capture the source of each ingested piece of data, the transformations applied during integration, and the confidence level associated with the integrated result. This provenance-aware integration enhances data quality assessment, allows users to evaluate the reliability of integrated data, and supports decision-making processes based on trustworthy and traceable information.
-
Cybersecurity and Intrusion Detection: In the realm of cybersecurity, data provenance plays a critical role in detecting and investigating security incidents. RDF databases can capture provenance information about data sources, data processing steps, and data flow within systems. By associating timestamps, metadata, and access control information with RDF triples, organisations can track the origin of suspicious data, identify potential vulnerabilities, and analyse the propagation of security breaches. Provenance-enabled RDF databases facilitate forensic analysis, incident response, and threat intelligence in the field of cybersecurity.
-
Data Lineage and Data Quality Analysis: Understanding the lineage of data is essential for assessing and ensuring data quality. RDF databases allow for capturing detailed data lineage information by associating provenance metadata with RDF triples. Data practitioners can trace the source of each piece of data, examine its transformation steps, and identify potential issues or anomalies. This lineage information supports data quality analysis, error detection, and data cleaning processes. RDF’s semantic representation also enables the integration of quality metrics and annotations, providing a comprehensive view of data quality within the database.
Use case: Applications requiring a Temporal Dimension
Statement-level annotations in RDF may be treated not just as literal values but as nodes connected to other nodes in the graph. This opens up the opportunity for representing the dimension of temporal entity events. For example, a node describing an employee can include an annotation with the date of the last task, which is in turn connected to the node representing this task. This allows for the enriching of the semantic description of nodes with temporal relationships, resulting in richer data queries.
By incorporating temporal aspects into a knowledge graph, it becomes possible to capture the temporal dimension of data, such as when facts were true or events occurred. This temporal information can be associated with entities, relationships, or individual statements within the graph. Temporal modelling techniques for knowledge graphs typically involve annotating data with timestamps or intervals to indicate when they were valid (similar to Slowly changing dimensions in relational models). This can be achieved using specialised temporal extensions or by representing time as an explicit dimension within the graph structure.
With temporal modelling in place, time travel queries can be executed to retrieve data as it existed at a specific point in time, or to project data into the future based on certain assumptions. These queries can be formulated to retrieve historical states, track changes over time, or make predictions about future states.
Example applications within this use case:
-
Historical Data Analysis: RDF databases are well-suited for analysing historical data, where capturing and analysing temporal information is crucial. Whether it’s studying historical trends, analysing long-term patterns, or conducting retrospective analyses, RDF databases excel at representing time-stamped data and capturing the evolution of information over time. By associating timestamps or temporal intervals with RDF triples, data scientists can track changes, perform trend analysis, and gain insights into how data has evolved over different time periods.
-
Event-based Data Processing: Applications that deal with event-based data often require capturing and processing events in a temporal context. RDF databases can effectively capture event data by associating events with timestamps, durations, or intervals. This temporal modeling allows for efficient event correlation, analysis of event sequences, and detection of temporal patterns or anomalies. Whether it’s analysing IoT sensor data, monitoring system logs, or processing real-time event streams, RDF databases provide a semantic foundation for event-based data processing and analysis.
-
Temporal Reasoning and Temporal Ontologies: RDF’s flexibility and support for ontologies make it an excellent choice for temporal reasoning and modeling of temporal knowledge. RDF databases can capture temporal ontologies that define temporal concepts, relationships, and reasoning rules. This enables data scientists to perform sophisticated temporal reasoning, such as temporal querying, temporal logic-based inference, and reasoning about temporal constraints. Applications that require temporal context awareness, such as scheduling systems, historical simulations, or temporal planning, can leverage RDF databases to incorporate temporal reasoning into their workflows.
-
Temporal Data Integration: RDF’s capability to integrate heterogeneous data from various sources is particularly useful when dealing with temporal data integration. RDF databases allow for seamless integration of data with different temporal granularities, resolutions, or representations. By mapping temporal data from different sources into RDF triples and applying temporal reasoning, data scientists can harmonise temporal data, resolve inconsistencies, and perform temporal integration across diverse datasets. This integration can be essential in applications that require combining temporal data from multiple domains, such as environmental monitoring, epidemiology, or financial analysis.
Use case: Applications with Cross-Domain Knowledge
Many advanced data-intensive applications like ‘smart’ homes need to integrate data from different domains and sources and make real-time inferences based on this data. The same capabilities are required by many IoT applications used in smart urban environments and various industrial settings.
RDF offers many advantages for such kinds of applications. In particular, RDF Graphs are more suitable than LPGs for modelling ontologies, a set of properties, relations, and categories that represent a specific domain or subject of the ‘smart’ component. It’s simpler to model ontologies thanks to its atomic decomposition of subjects and relations, global uniqueness of nodes and edges, and built-in shareability of data.
Ontologies implemented via RDF enable cross-domain data sharing, data interoperability, expert systems, and the domain-based inference required by many IoT applications. In contrast, the arbitrary data design used in LPG makes it harder to implement ontologies in LPG-based graphs, thus making the LPG architecture less suitable for cross-domain data sharing and domain-based inference.
Example applications within this use case:
-
Semantic Search and Recommendation Systems: RDF databases excel in applications that require semantic search and recommendation systems. By representing data using RDF triples, RDF databases enable the integration of diverse data sources and knowledge domains. This integration empowers search engines and recommendation systems to provide more precise and context-aware results. RDF’s semantic model facilitates better understanding of user queries, matching them with relevant entities, relationships, and context from various domains. This cross-domain knowledge enhances search accuracy, semantic relevance, and recommendation quality.
-
Data Analytics and Insights: RDF databases facilitate data analytics and insights by providing a semantic framework for integrating and analysing data from multiple domains. By capturing relationships and context using RDF triples, organisations can gain a comprehensive understanding of complex datasets. RDF’s flexible structure allows for the incorporation of diverse data sources, including structured data, unstructured text, multimedia, and sensor data. Integrating cross-domain knowledge enables advanced analytics, pattern recognition, and data-driven insights that transcend individual domains, leading to more informed decision-making and innovation.
-
Interdisciplinary Research: RDF databases are particularly valuable in interdisciplinary research, where insights from multiple domains need to be combined and analysed. By representing knowledge using RDF triples, researchers can capture and integrate diverse information, methodologies, and perspectives from different disciplines. RDF’s semantic model enables the representation of relationships, dependencies, and interdisciplinary connections, fostering collaboration and knowledge sharing across domains. RDF databases facilitate interdisciplinary research by providing a shared knowledge representation that transcends disciplinary boundaries.
-
Contextualised Data Integration: Applications that require contextualised data integration can benefit greatly from RDF databases. RDF’s flexible data model allows for the representation of contextual information alongside data from multiple domains. By associating metadata, contextual attributes, and provenance information with RDF triples, applications can capture the context in which data was generated, the purpose it serves, and the relationships it has with other data. This contextualisation enhances the meaning and relevance of integrated data, providing a more comprehensive view and facilitating informed analysis and decision-making.
Use case: Data Science and Analytics
RDF graphs provide a powerful and flexible approach to data modelling that offers several benefits for data science and analytics. When compared to Labeled Property Graphs (LPGs), RDF graphs bring unique advantages that make them particularly suitable for certain data-intensive use cases.
Example applications within this use case:
-
-
Standardised Semantic Representation: RDF follows a standardised semantic data model, which means that data in RDF graphs can be easily understood and interpreted by different systems and tools. This semantic representation enables seamless data integration from diverse sources, allowing data scientists to merge and analyse data from various domains and platforms. RDF’s standardised structure also facilitates interoperability and data exchange, making it easier to collaborate and share data with other researchers and organisations.
-
Knowledge Representation and Inference: RDF’s ability to represent knowledge using ontologies and semantic models brings significant advantages as they can capture domain-specific knowledge, relationships, and semantic hierarchies. This knowledge representation facilitates advanced reasoning and inference, enabling data scientists to derive new insights, make logical deductions, and discover implicit relationships in the data. RDF’s foundation in formal mathematical logic provides a robust framework for performing complex queries and reasoning tasks.
-
-
Linked Data Integration: RDF’s core principle of linking data through URIs (Uniform Resource Identifiers) makes it highly compatible with the Linked Data concept. Linked Data allows for the integration and interlinking of data across different sources, creating a vast web of interconnected information. For data scientists and analysts, this means access to a wealth of diverse and interlinked data that can be leveraged to enrich their analyses, gain a broader context, and discover new patterns and relationships across an organisation
-
SPARQL Querying and Reasoning Capabilities: SPARQL allows for expressive querying and advanced graph pattern matching. RDF’s inherent support for reasoning and inference also enhances the query capabilities, enabling data scientists to ask more complex questions, explore data relationships, and perform advanced analytics tasks.
Key Differences: RDF Knowledge Graphs and Labelled Property Graphs
|
Feature |
RDF |
Property Graph |
|
Expressivity |
Arbitrary complex descriptions via links to other nodes; no properties on edges With RDF* the model gets much more expressive than LPG |
Limited expressivity, beyond the basic directed cyclic labeled graph |
|
Formal semantics |
Yes, standard schema and model semantics foster data reuse and inference |
No formal model representation |
|
Standardisation |
Driven by W3C working groups and standardisation processes |
Different competing vendors |
|
Query language |
SPARQL specifications: Query Language, Updates, Federation, Protocol (end-point)… |
Cypher, PGQL, GCore, GQL (no standard) |
|
Serialisation format |
Multiple serialisation formats |
No serialisation format |
|
Schema language |
RDFS, OWL, Shapes |
None |
|
Designed for |
Linked Open Data (Semantic Web): Publishing and linking data with formal semantics and no central control |
Graph representation for analytics |
|
Processing Strengths |
Set analysis operations (as in SQL, but with schema abstraction and flexibility) |
Graph traversal |
|
Data Management Strengths |
Interoperability via global identifiers Interoperability via a standard: schema language, protocol for federation, reasoning semantics Data validation, data type support, multilinguality |
Compact serialisation, shorter learning curve, functional graph traversal language (Gremlin) |
|
Main use cases |
|
|
Graph Query Languages: SPARQL vs. Cypher
SPARQL
SPARQL (pronounced “sparkle”) is a declarative graph query language that was developed by the World Wide Web Consortium (W3C) as a standard for querying RDF (Resource Description Framework) data. RDF is a data model that is used to represent information on the web, making SPARQL particularly well-suited for querying linked data and semantic web applications. SPARQL is supported by a variety of RDF stores, such as Virtuoso, Stardog, and GraphDB, as well as some graph databases like Neo4j and Amazon Neptune.
Cypher
Cypher is a declarative graph query language developed by Neo4j, one of the leading graph database platforms. It is designed to be expressive and easy to read, with a syntax that closely resembles natural language. This makes it a great choice for developers who are new to graph databases, as well as for those who prefer a more human-readable query language. Cypher is optimised for querying Neo4j databases, but it has also been adopted by other graph database platforms, such as SAP HANA Graph and RedisGraph.
The table below contains an informal mapping of the SPARQL and Cypher constructs.
|
Cypher |
SPARQL |
|---|---|
|
CREATE |
INSERT |
|
RETURN |
SELECT |
|
WITH |
SELECT in a sub query |
|
MATCH |
WHERE |
|
WHERE |
FILTER |
|
:label |
owl:Class or rdfs:Class |
|
[edge] |
Predicate <edge> or |
|
(node) |
a graph node (blank or IRI) |
|
var:Person |
?var a :Person |
|
var.name |
?name assuming a match ?var <name> ?name |
|
nodeVar: label {key value, key2 value2} |
?nodeVar a label: <key> value;key2 value2. |
|
(ee)-[:KNOWS {since: 2001}]->(js) |
<< ?ee <knows> <js> >> <since>2001 |
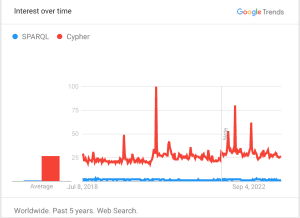
A quick look at Google trends shows a striking dominance of searches for Cypher rather than SPARQL, illustrating the level of market share currently held by Neo4j
Bloor Research’s Graph Database Market Update 2023
Bloor would argue that the market leaders in this space continue to be Neo4J and OntoText (GraphDB), which are graph and RDF database providers respectively. However, www.db-engines.com suggests that MarkLogic is the leader in the RDF space. This is a question of definition: GraphDB is a pure-play RDF database with multi-model capabilities while MarkLogic is a multi-model database with an underlying XML engine that offers RDF capabilities. In any case, they are both leading vendors in this space, along with Amazon Neptune.

Full report below:
Graph Databases (Technology) – Bloor Research
